TanStack Queryを試してみて、API取得の設計を見直した話
公開日:
タグ:
- #Next.js
- #React
Tanstack Queryとは
JavaScriptやTypeScriptを使ったアプリ、(ReactやVueなどのフレームワーク)で、サーバーから取得した非同期のデータを効率良く管理するためのライブラリです。
主に以下のような役割を持ちます。
- APIからのデータ取得
- 取得データのキャッシュ
- ローディング、エラー状態の管理
- 再取得の制御
今回、試しに使ってみて色々と気づきがあったのでそれをメモしておきたいと思います。
作ったもの
テストで作ってみたものはこちら。
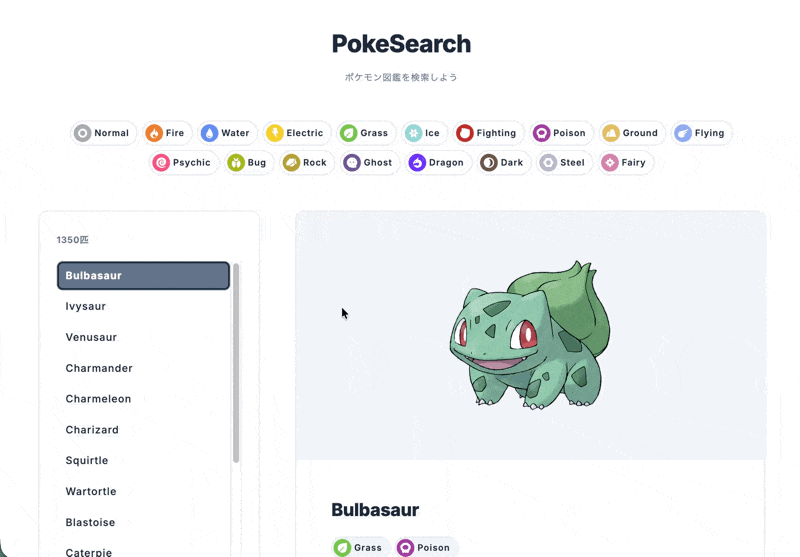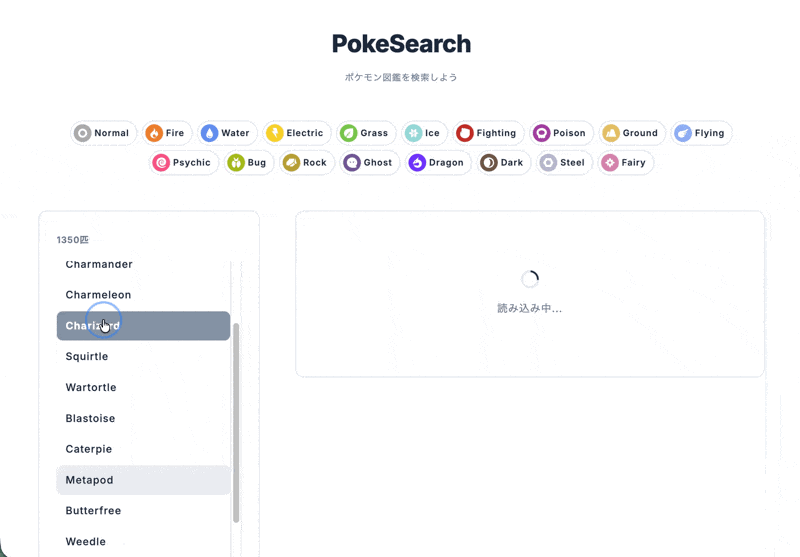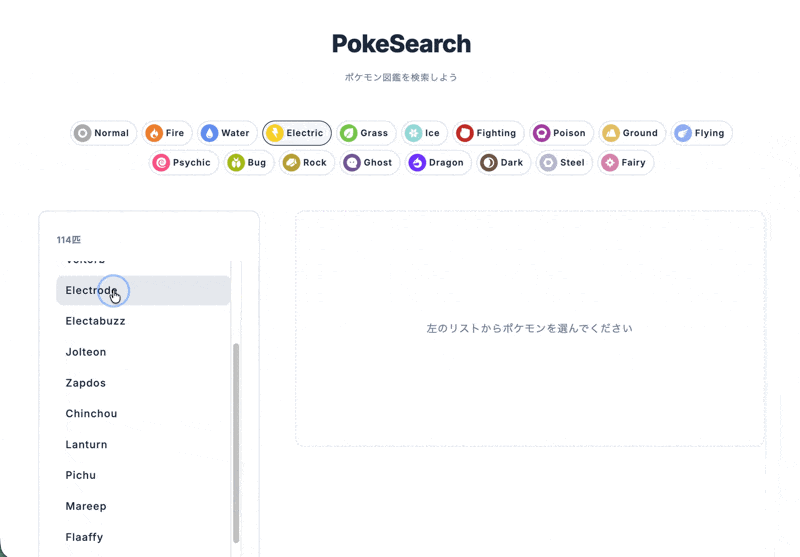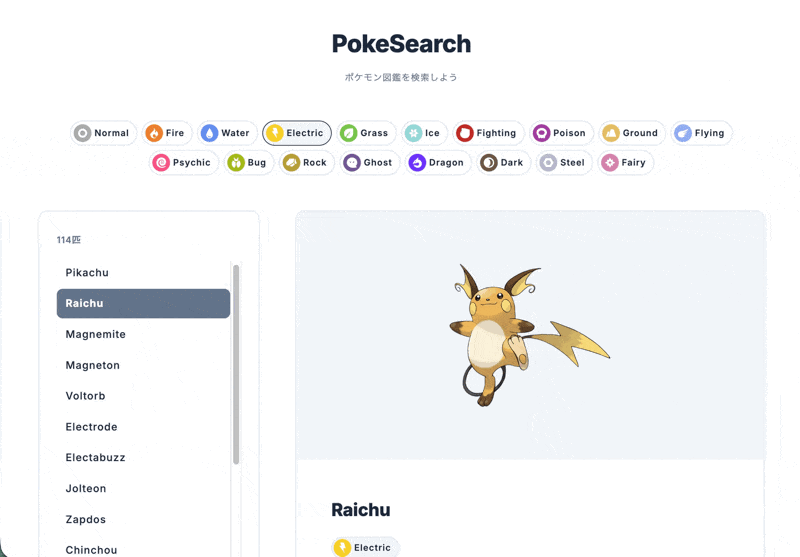
PokéAPIを利用して、
- 全ポケモンの一覧表示
- タイプごとの一覧表示
- 詳細情報の表示
ができるWebページを作りました。
フレームワークはNext.jsを使用しています。
TanStack Queryを使用してみる
まずは QueryClientProvider を用意します。
'use client'
import {
QueryClient,
QueryClientProvider,
} from '@tanstack/react-query';
export function Provider({ children }: { children: React.ReactNode }) {
const queryClient = getQueryClient();
return (
<QueryClientProvider client={queryClient}>{children}</QueryClientProvider>
);
}
作成した Provider を layout.tsx 内でラップします
import { Provider } from '@/provider';
export default function Layout({
children,
}: Readonly<{
children: React.ReactNode;
}>) {
return (
<html lang="ja">
<body>
<main>
<Provider>{children}</Provider>
</main>
</body>
</html>
);
}
データの取得は、以下のように useQuery を使って行います。
以下は、ポケモンの詳細情報の取得例です。
import { useQuery } from '@tanstack/react-query';
const { data, isLoading, isError, error } = useQuery({
queryKey: ['pokemonDetail', name],
queryFn: () => fetchPokeDetail(name),
enabled: !!name,
staleTime: 1000 * 60 * 5,
});
useQuery の queryFn にAPIの情報を取得する関数を渡します。queryKey に name を含めることで、
- ポケモンごとにキャッシュが分類される
- 一度表示した詳細は再取得されない
という動作になります。
使ってみて気づいたこと
そもそもTanStack Queryが必要なのか?
最初はTanStack Queryを使うために全データをClient Componentsで取得するような形にしていましたが、実装を進めていくうちに以下のように整理しました。
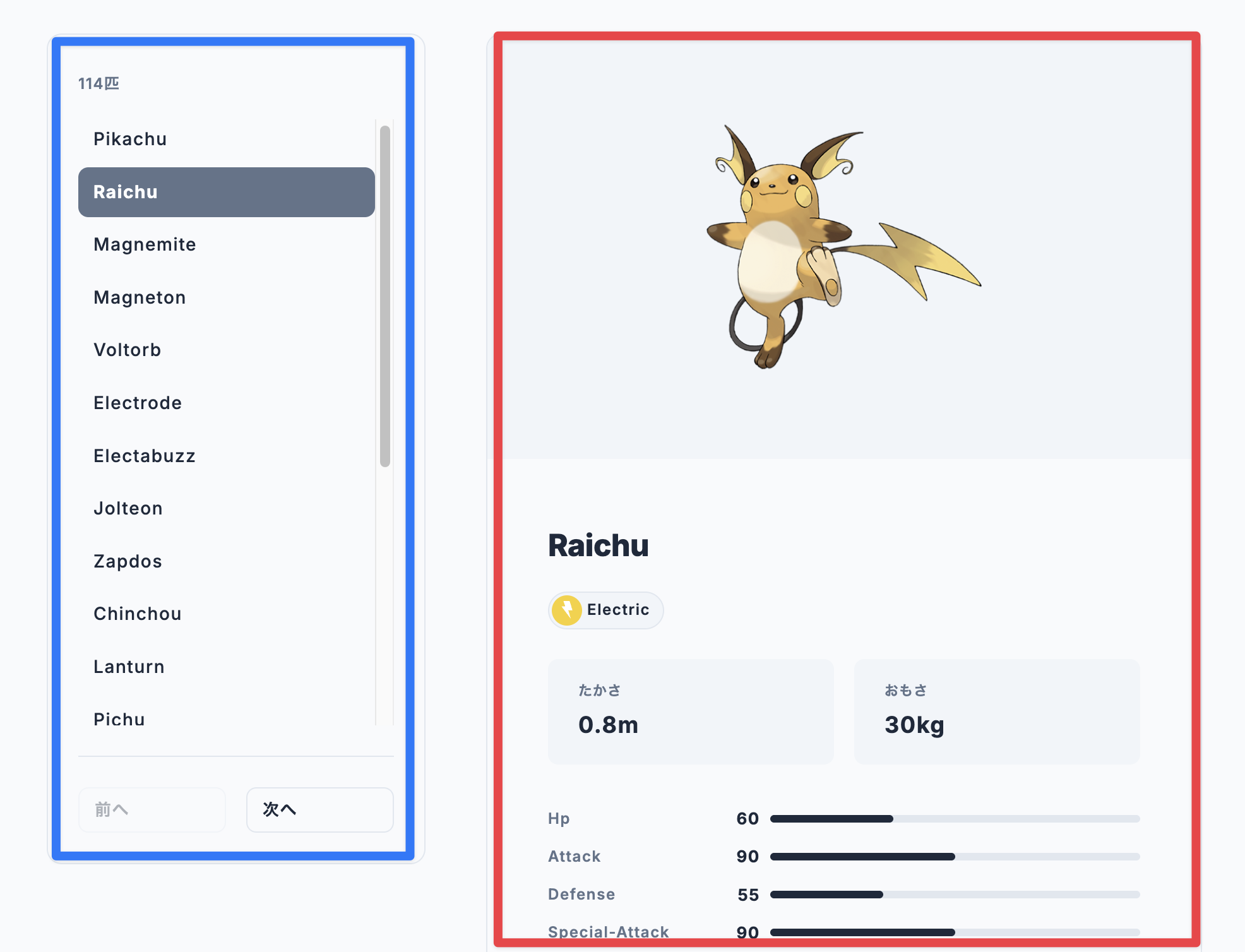
一覧・タイプ一覧(青枠部分)
/pokemonで全ポケモン一覧を全件取得/type/{typeName}でタイプ別一覧を全件取得- どちらも Server Components で取得
- Next.jsの
fetch、revalidateでサーバーキャッシュを管理する形に - サーバーサイドレンダリングして一覧が入ったHTMLを返すようにした
上記のように実装した理由は
- 一覧は初回表示に必要
- 頻繁に変わるデータではない
- 何度もAPIを叩く必要がない
ためです。
そのためClient Componentsで取得する必要はなく、Server側で取得してpropsとして渡す構成にしました。
またAPIの都合上、ページ送り時もAPIは叩かず、クライアント側でロジックを処理しています。
詳細表示(赤枠部分)
一方、詳細表示部分は以下のようなUIになっています。
- ページ遷移しない
- 左の一覧をクリックすると右側が切り替わる
この構成だと、
- ユーザーが何度も同じポケモンを開く可能性がある
- 表示のたびにAPIを叩くと無駄が多い
という特徴があります。
ここでTanStack Queryのクライアントキャッシュが有効に働きました。
一度取得したポケモンの詳細はキャッシュされるため、
- 別のポケモンを開く
- また元に戻る
という操作でも、再取得せず即表示されます。
Next.js側のキャッシュとの役割分担
今回の構成では、キャッシュを以下のように分けています。
一覧データ
→ Server Components側で取得し、サーバーキャッシュを利用
詳細データ
→ Client側ではTanStack Queryでキャッシュ
→ さらにサーバー側でもキャッシュ
つまり、
- サーバーキャッシュ:APIへのリクエスト自体を減らす
- クライアントキャッシュ:同じ詳細を再表示する時の体感速度を上げる
という二層構造になっています。
特に今回利用しているPokéAPIは有志で運営されているAPIのため、
prefetchなどは行わず、なるべくリクエスト回数は制限しつつ、キャッシュを利用して同じリクエストを繰り返さない設計にしました。
TanStack Queryが有効だと感じたシーン
今回の検証で感じたのは、
「Client側で頻繁に切り替わるデータ」にはかなり有効である
ということです。
特に今回のような:
- ページ遷移なし
- 選択によって詳細だけが切り替わるUI
では、キャッシュの恩恵が分かりやすく感じられました。
逆に、使わなくても良かった部分
最初はすべてClient ComponentsでAPIを取得しようとしていました。
ただ実装を進める中で、
- 一覧は初回に必ず必要
- Serverで取得した方が自然
- APIの呼び出し回数も減る
と気づき、Server Componentsに寄せました。
結果として、
- 一覧 → Server
- 詳細 → Client + TanStack Query
という役割分担に落ち着きました。
まとめ
今回触ってみて感じたのは、以下のようなケースで特に有効だということです。
- Client Componentsでデータ取得が頻繁に発生する
- 同じデータを何度も表示する可能性がある
- ユーザー操作に応じて表示が切り替わる
逆に、
- 初回表示に必ず必要なデータ
- 更新頻度が低いデータ
はServer Componentsで取得する方がシンプルでした。
TanStack Queryを試しに使ってみたことで、API取得の設計を改めて見直すきっかけになりました。
用途を見極めながら、今後の実装にも活かしていきたいと思います。